Razvojem tehnologija mobilnog poslovanja, interneta inteligentnih uređaja i društvenih medija povećava se količina podataka koja se čuva u informacionim sistemima preduzeća.
Zahtevi za razvojem naprednih aplikacija elektronskog poslovanja, koje odlikuje pouzdanost, distribuiranost i skalabilnost, ne mogu se realizovati primenom tradicionalnih baza podataka. Zato se razvijaju novi pristupi za skladištenje,brzu pretragu i analizu velikih količina podataka u realnom vremenu, zasnovani na Big data tehnologijama.
Potreba za primenom Big data tehnologija često se objašnjava korišćenjem tri „V“ modela, po kome su glavne karakteristike Big data :
- Obim podataka (Volume)
- Raznovrsnost podataka (Variety)
- Brzina (Velocity).
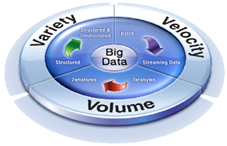
Slika1: Dimenzija Big Data
Da bi se omogućilo pouzdano i skalabilno skladištenje velikih količina podataka,neophodno je obezbediti čuvanje i upravljanje fajlovima u distribuiranom okruženju. Za to se koriste distribuirani fajl sistemi koji omogućuju jednostavan pristup fajlovima na različitim lokacijama, replikaciju fajlova između servera i kompresiju podataka optimizovanu za transfer kroz mrežu sa ograničenom propusnom moći.
Primeri za implementaciju distribuiranih fajl sistema: Google File System (GFS) , Hadoop distributed file system (HDFS) , GlusterFS.
Velike količina podataka koje se generišu u IoT aplikacijama stvaraju teškoće u korišćenju relacionih baza podataka, zato je neophodno uprostiti relacioni model i realizovati jednostavnije mehanizme za čuvanje. Skalabilne, distribuirane i pouzdane baze podataka realizuju se na osnovu nekog od sledećih modela nerelacionih baza podataka: Ključ-podatak model,BigTable model,Dokument model,Graf model.
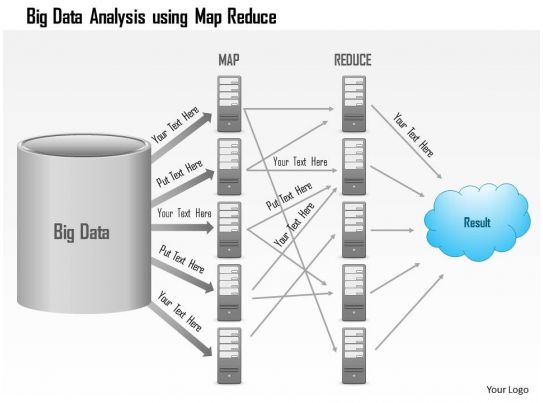
Standardni mehanizmi pretrage ne zadovoljavaju u pogledu brzine obrade podataka kada se primenjuju u Big data okruženju, zbog čega je realizovan jedan od novih pristup pod nazivom MapReduce. Gugl je 2010. patentirao ovaj algoritam koji pretražuje podatke uređene po parovima: ključ, podatak (k,v). Algoritam se koristi kao osnovni mehanizam za pretraživanje i izveštavanje u većini Big data baza podataka.
U Big data analitici koriste se različite tehnike, kao što su : Klaster analiza,Pravila pridruživanja, Klasifikacija, Mašinsko učenje, Neuronske mreže, Mrežna analiza,Optimizacija,Analiza segmenata,Integracija podataka,Genetski algoritmi.
Hadoop okvir za Big data
Hadoop je softverski okvir otvorenog kôda za skladištenje, pretragu i analizu velikih količina podataka. Napisan je u Java programskom jeziku. Hadoop ekosistem obuhvata više komponenti i alata.
Osnovni elementi Hadoop ekosistema su :
- Hadoop Common. Osnovni paketi za podršku radu ostalih modula.
- Hadoop Distributed File System. Distribuirani fajl sistem koji aplikacijama omogućuje brz pristup podacima.
- Hadoop YARN. Modul za upravljanje resursima u klasteru i za upravljanje izvršenjem poslova.
- Hadoop MapReduce. Komponenta za paralelno procesiranje velikih skupova podataka primenom MapReduce algoritma.
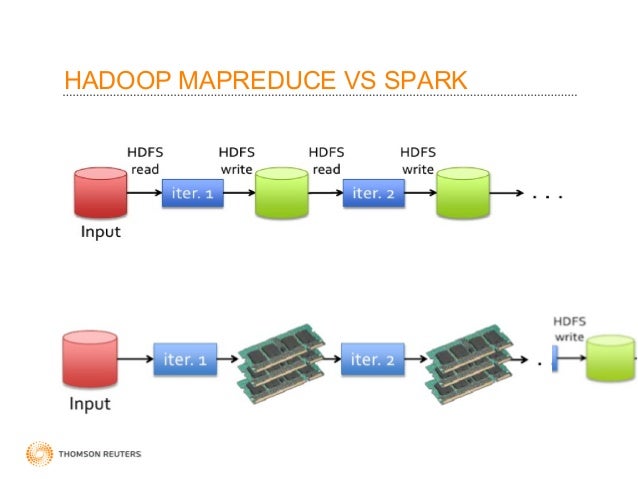
Hadoop je dizajniran za podršku batch obradi podataka i kao takav nije pogodan za obradu podataka u realnom vremenu. Za obradu podataka u realnom vremenu koriste se Apache Storm ili Apache Spark, sistemi otvorenog kôda, koji se lako mogu integrisati sa Hadoop infrastrukturom.
Apache Spark
Apache Spark je softver otvorenog kôda za distribuiranu obradu podataka u realnom vremenu. Za razliku od Hadoop-a, zasnovan je na in-memory računarstvu.Korisničkim programima omogućeno je da učitaju velike količine podataka u memoriju, pa se pretraga i obrada podataka vrši u memoriji, a ne na diskovima.
Big data tehnologije mogu se primeniti u brojnim oblastima IoT: poslovanju,medicine, obrazovanju, u transport I saobraćaju, u meteorologiji, u naučnim istraživanjima, u javnoj upravi.
IoT sistemi predstavljaju senzorske mreže u kojima se generiše velika količina podataka. Primena Big data u IoT rešenjima omogućuje pouzdano, distribuirano I skalabilno čuvanje i korišćenje velikih količina podataka, uz očuvanje njihove bezbednosti i privatnosti korisnika.
